3.13 학습 내용
0501
=> 머신러닝의 지도학습의 분류를 사용하는 Scikit-learn API 기초와 DecisionTree 를 실습, 수치데이터만 사용
0502
=> 범주형 데이터를 인코딩(수치 데이터로 변환)해서 사용하는 방법,
One-Hot-Encoding(pd.get_dummies), RandomForest
0503 => One-Hot-Encoding(scikit-learn), 언더피팅, 오버피팅을 평가시 train, test 데이터에 대한 점수 비교.
기존에는 test 데이터에 대해서만 평가했는데 train 데이터로 평가해볼 예정입니다.
cross validation 기법을 사용해서 평가해볼 예정입니다.
요약정리
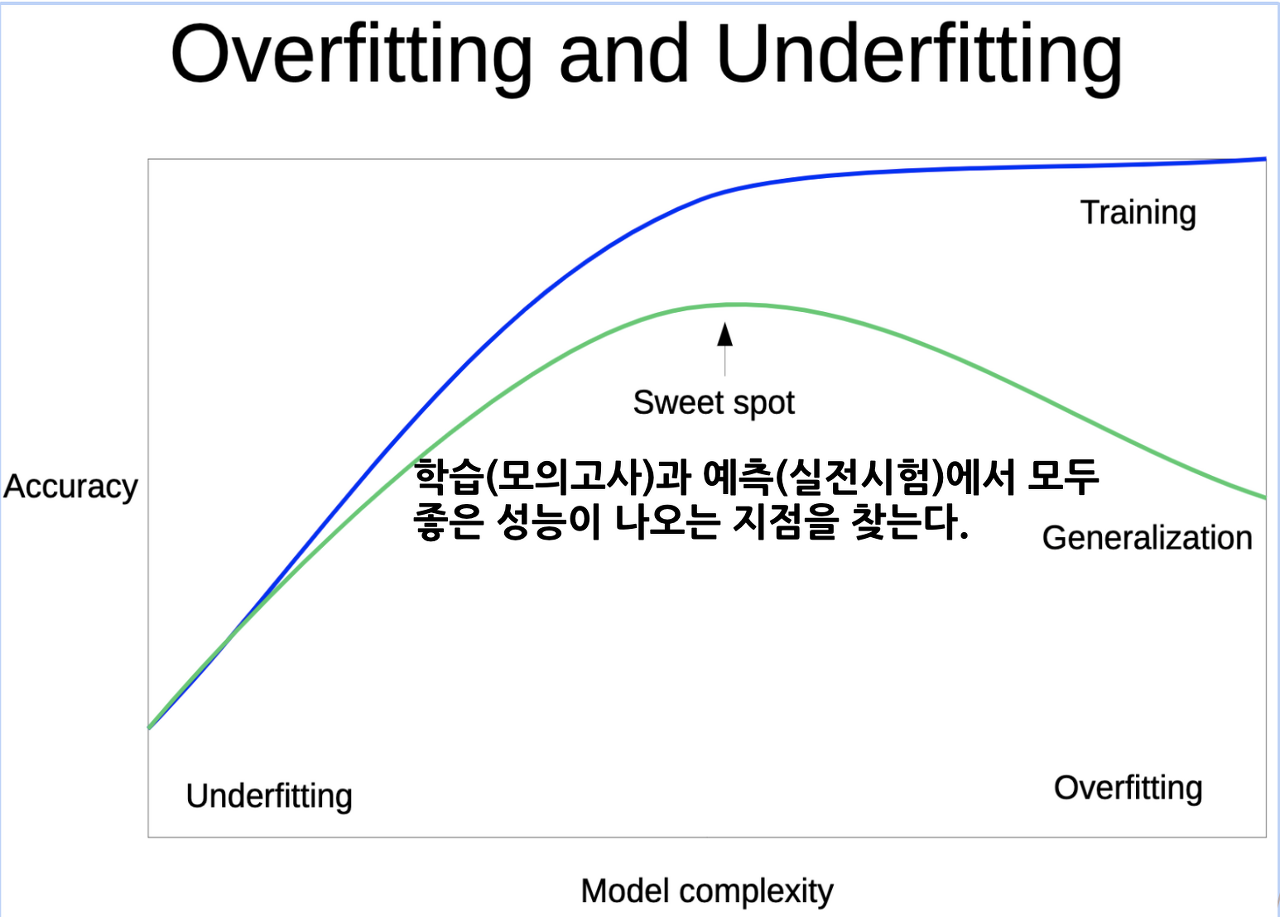
underfitting과 overfitting
언더피팅(underfitting) 은 모델이 학습 오류를 줄이지 못하는 상황을 의미,
오버피팅(overfitting)은 모델 학습 오류가 테스트 데이터의 오류보다 훨씬 작은 경우를 의미

손실함수(Loss function)
> 예측값과 실제값(레이블)의 차이(loss)를 구하는 기준. 머신러닝 모델 학습에서 필수 구성요소.
손실함수로 인해 모델의 성능이 달라질 수 있어, 어떠한 손실함수가 최적일지 고민.
Ordinal encoding과 One hot encoding
> 범주형 변수(categorical variable)를 수치형 변수(numerical variable)로 변환하는 방법.
- Ordinal encoding은 범주형 변수에 정해진 순서나 등급이 있을 때 사용.
- One hot encoding은 범주형 변수의 모든 값을 이진수(binary)로 표현하는 방법.

Ordinal encoding
예를 들어, 옷의 크기를 나타내는 S, M, L, XL과 같은 값은 순서가 있으므로 이러한 범주형 변수를 정수값으로 변환.
> 크기 순서에 따라 S=1, M=2, L=3, XL=4과 같은 방식으로 범주를 정수로 매핑.
One hot encoding
예를 들어, 색상이 빨강, 파랑, 노랑으로 구분되는 경우, One hot encoding을 사용시 각 색상을 0 또는 1의 값으로 변환.
> 빨강은 [1, 0, 0], 파랑은 [0, 1, 0], 노랑은 [0, 0, 1]과 같은 방식으로 범주형 변수를 변환.
> 각 범주에 대해 하나의 이진 변수를 만들어 해당 범주에 해당하는 경우 1, 아니면 0으로 표현.
Ordinal encoding과 One hot encoding 각각의 장단점.
- Ordinal encoding은 범주형 변수의 순서나 등급을 반영하여 정보를 유지할 수 있지만,
변수의 크기가 순서와 상관 없이 숫자로 표현되기 때문에 모델 학습에 문제가 발생.
- One hot encoding은 범주형 변수의 모든 값을 고려하여 정보를 유지하지만,
변수가 많아질수록 변환된 변수의 차원이 늘어나게 되어 모델 학습에 필요한 데이터의 양이 증가 가능.
원핫인코딩을 할 때 결측치는 고려하지 않습니다.
결측치를 원핫인코딩에 반영하고자 한다면 문자 데이터로 "NA" 혹은 "없음" 등으로 값을 만들어주어야 반영이 됩니다.
결측치를 채우는 방법도 있지만 결측치가 너무 많은데 해당 변수를 사용하고자 할 때는 범주화 해서 사용
범주형 데이터를 수치형 데이터로 바꾸는 feature engineering 방법!
(feature engineering이란? 데이터 전처리 기법 중 하나로, 변수를 변환하거나 새로운 변수를 생성하는 등의 과정을 통해 유의미한 변수로 만들어내는 것)
장점 : 모든 머신러닝 알고리즘에서 사용 가능하다 범주형 변수를 수치형 변수로 변환해 주므로, 모델이 변수 간 상관관계를 파악할 수 있다. 범주형 변수의 카테고리 수가 많아져도 적용할 수 있다.
단점 : 카테고리 수가 많은 경우, 변수의 차원이 늘어남. -> 차원의 저주 문제 / 모델 학습 속도 저하 카테고리 수가 적은 경우 희소 행렬 생성 -> 데이터셋 크기가 커져 메모리, 처리 속도에 부담
train, test의 피처를 동일하게 만들어 주어야 학습과 예측을 할 때 오류가 생기지 않음!
> train과 test를 각각 따로 인코딩 하면 컬럼순서, 개수가 달라질 수 있습니다.
> 다른 피처를 사용하면 학습했을 때 오류가 발생!! -> train으로 맞춰주는 작업 필요
scikit-learn에서 fit, transform을 할 때 trian에만 fit을 해주는 이유와도 같음
stratify
train_test split에서 사용하는 파라미터로, train과 test 데이터에 클래스 비율을 동일하게 나눠줍니다.
stratify값을 target 값으로 지정해주면 target의 class 비율을 유지 한 채로 데이터 셋을 split 하게 됩니다.
만약 이 옵션을 지정해주지 않고 classification 문제를 다룬다면, 성능의 차이가 많이 날 수 있습니다
Data Leakage(데이터 누수)
데이터 유출(또는 누수)은
학습 데이터에 대상에 대한 정보가 포함되어 있지만 예측에 모델을 사용할 때 유사한 데이터를 사용할 수 없을 때 발생.
> 이로 인해 학습 세트(및 검증 데이터)의 성능은 높아지지만, 실제 운영 환경에서는 모델의 성능이 저하.
> 누수가 발생하면 모델을 사용하여 의사 결정을 내리기 전까지는 모델이 정확해 보이지만 그 이후에는 모델이 매우 부정확해짐
배깅(bagging)
> bootstrap aggregating의 줄임말
> 통계적 분류와 회귀 분석에서 사용되는 기계 학습 알고리즘의 안정성과 정확도를 향상시키기 위해 고안된 일종의 앙상블 학습법의 메타 알고리즘이다.
> 배깅은 분산을 줄이고 과적합(overfitting)을 피하도록 해준다.
> 결정 트리 학습법이나 랜덤 포레스트에만 적용되는 것이 일반적이기는 하나, 그 외의 다른 방법들과 함께 사용할 수 있다.
Q&A
Q. 학습모델 생성. 99%의 정확도 도출?
A. 정답을 학습데이터에 포함시킬 경우 제대로 학습하기 어려움. 정확도 100% 근사 도출
Q. 의사결정나무(Decision Tree)의 단점?
A.
- Overfitting 문제: Decision tree는 학습 데이터에 과도하게 학습할 수 있어서, 과적합(overfitting)이 발생하기 쉽습니다. 이러한 문제를 해결하기 위해 pruning 등의 기법이 사용.
- 결정 경계의 수직/수평선 문제: Decision tree는 분류 경계를 수직 또는 수평선으로만 설정하기 때문에, 데이터가 대각선 방향으로 구분되는 경우 결정 경계를 잘 파악하지 못할 수 있습니다.
- 불균형 데이터셋 처리 문제: Decision tree는 불균형한 데이터셋에서 성능이 저하될 수 있습니다. 이는 일부 클래스에 대한 샘플이 다른 클래스보다 매우 적은 경우에 특히 더 큰 문제가 됩니다.
- 연속형 변수 처리 문제: Decision tree는 연속형 변수를 처리하기에 적합하지 않습니다. 일반적으로 연속형 변수를 범주형 변수로 변환한 후에 사용.
- Robustness 문제: Decision tree는 데이터의 작은 변화에도 결과가 크게 변할 수 있습니다. 따라서, 노이즈가 있는 데이터나 이상치(outlier)가 있는 데이터에서 성능이 저하될 수 있습니다.
랜덤 포레스트(Random Forest)에서 트리의 개수는 많을수록 좋은 성능을 보이지만, 일반적으로는 시간과 메모리 제약으로 인해 적절한 개수를 선택해야 합니다. 적당한 트리의 개수는 데이터셋의 크기와 특성, 그리고 모델의 복잡도에 따라 다를 수 있습니다. 보통은 수백에서 몇 천 개 정도의 트리를 사용하는 것이 일반적입니다. 작은 데이터셋의 경우 10-20개 정도의 트리를 사용하기도 합니다. 반면, 매우 큰 데이터셋이거나 복잡한 문제의 경우 10,000개 이상의 트리를 사용하기도 합니다. 트리의 개수는 너무 적으면 과소적합(underfitting)되어 성능이 낮아지고, 너무 많으면 과대적합(overfitting)되어 성능이 떨어질 수 있습니다. 적당한 트리의 개수를 선택하기 위해서는 교차 검증(cross-validation) 등의 방법을 사용하여 모델의 성능을 평가하고, 최적의 개수를 찾아야 합니다.
교차 검증(cross-validation)
테스트 데이터를 제외한 무작위로 중복되어 있지 않은 k개의 데이터로 분할 (k-1) 개는 학습 데이터로 사용 나머지 1개의 데이터를 검증 데이터로 사용.
그리드 서치(grid search)
하이퍼 파라미터가 가능한 모든 조합을 시도하여 최적의 파라미터 값을 찾는 방법 파라미터: 데이터 학습을 통해 자동으로 그 값을 결정 하이퍼 파라미터 : 사용자가 경험적으로 그 값을 결정
'멋쟁이사자처럼 AI School 8기(fin) > TIL(Today I Learn)' 카테고리의 다른 글
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.20), RandomSearchCV (0) | 2023.03.20 |
|---|---|
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.17 ) - 태블로3 with 강승일 (0) | 2023.03.17 |
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.10 ) - 태블로2 with 강승일 (0) | 2023.03.10 |
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.8), 머신러닝 (0) | 2023.03.08 |
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.7), 머신러닝 (0) | 2023.03.07 |


