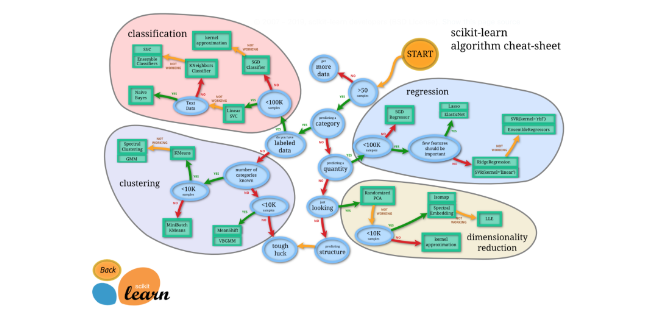
Scikit-learn
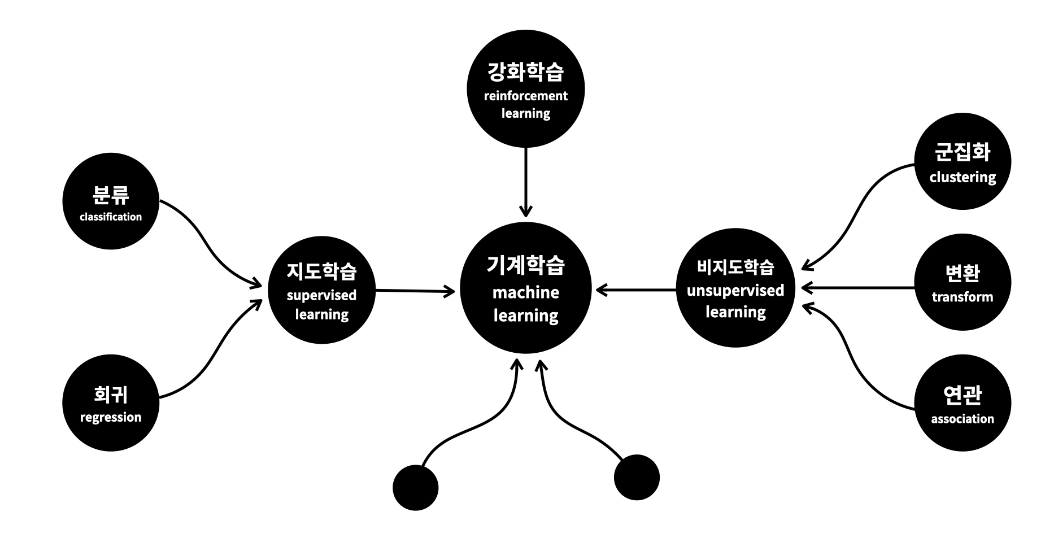
지도학습 vs 비지도학습
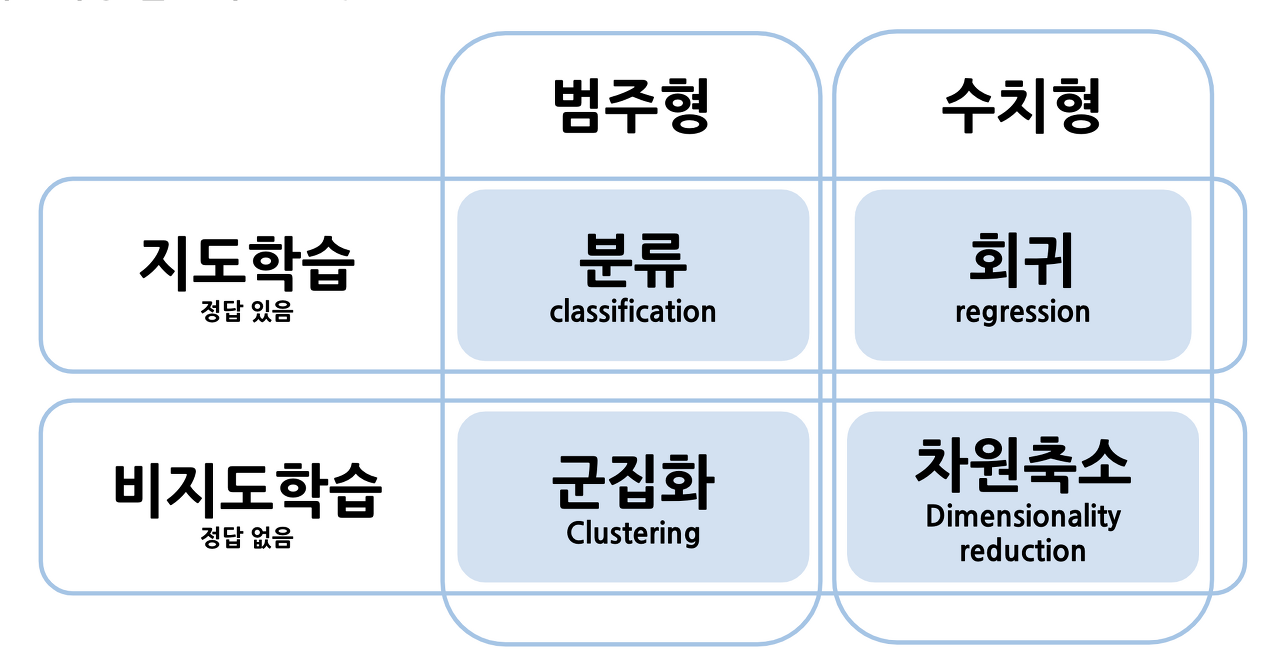
지도 학습
> 정답(Label) 있는 데이터를 학습
- 분류 : 범주형 데이터를 각 class별로 나누는 것 (범주형 변수)
- 회귀 : 하나의 가설에 미치는 다양한 수치형 변수들과의 인과성 분석 (수치형 변수)
비지도 학습
> 정답(Label) 없는 데이터를 학습
- 군집화 : 유사도가 높은 범주끼리 모아주는 것, 분류와는 다르게 정답이 없다. (범주형 변수)
- 차원축소 : 고차원 데이터를 차원을 축소해서 분석할 특성을 줄이고 한눈에 볼 수 있게 해줌 (수치형 변수)
No Free Lunch Theorems for Optimization
> Wolpert와 Macready가 1997년에 발표한 논문,
> 어떤 최적화 알고리즘이든 모든 문제에서 효과적일 수 없음.
> 최적화 문제의 성격에 따라서 알고리즘의 성능이 다르게 나타난다
> 최적화 알고리즘을 선택할 때는 문제의 특성에 적합한 알고리즘을 선택해야 한다는 것이 중요.
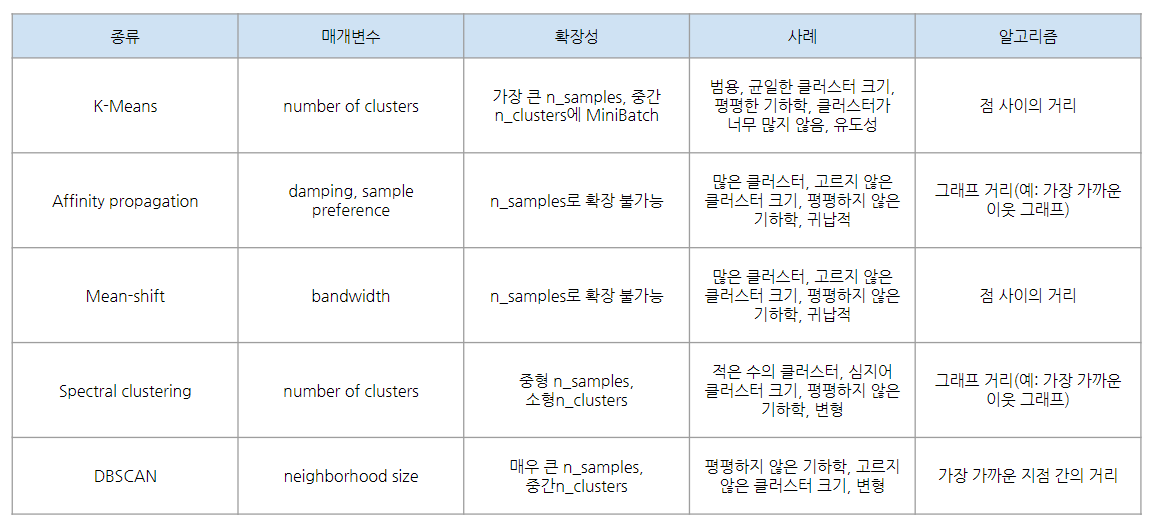
머신러닝 > 비지도학습 > 군집화 > K-means
특정 알고리즘(특히 회귀, 군집화) 한쪽에 치우친 데이터의 경우 잘 학습하지 못함
-> cut을 사용하여 데이터를 구간화
-> 혹은 log를 사용하여 정규분포로 만들어줌
로그변환

로그 변환시 : x + 1.
> x 값이 1보다 작을 때 마이너스 무한대로 수렴을 하기 떄문에, 가장 작은 값인 1 합산.
> np.log1p 를 사용.

Q. 음수가 있는데 분포가 한쪽으로 너무 치우쳐져있어서 로그를 적용해서 변환하고자 합니다.
그런데 음수에 로그를 적용할 수가 없습니다. 이 때는 어떻게 해야 할까요?
A. 음수에 로그를 적용할 수 없는 경우, 일반적으로 다음과 같은 방법들이 사용됩니다.
1) Min-max scaling: 데이터를 최소값을 0으로, 최대값을 1로 변환합니다. 그 후, 변환된 값을 다시 로그를 적용합니다.
2) Box-Cox 변환: Box-Cox 변환은 양수 데이터에 대해 사용되는 데이터 변환 방법 중 하나입니다. 음수 값을 변환하기 위해서는 먼저 상수를 더해서 모든 값이 양수가 되도록 만들어줍니다. 그 후에 Box-Cox 변환을 적용하고, 변환된 값을 다시 원래 상수를 빼서 원래 음수 값을 얻어낼 수 있습니다.
3) Yeo-Johnson 변환: Yeo-Johnson 변환은 Box-Cox 변환과 비슷한 방법으로 음수 값을 처리합니다. Box-Cox 변환에서는 음수 값을 처리하지 못하는데 비해 Yeo-Johnson 변환은 모든 값을 처리할 수 있습니다.
위의 방법들은 모두 데이터 분포를 변환하여 좀 더 대칭적이고 정규성을 가진 분포로 변환하여 분석할 수 있도록 도와줍니다.
Elbow Method
Inertia : 각 군집별 오차의 제곱의 합, 군집 내의 분산 k가 증가하면 inertia가 줄어들게 됨
inertia가 빠르게 변하는 지점이 최적의 k
실루엣 계수
- EM알고리즘만으로는 "적당한" K를 찾기 모호하다는 한계점을 보안하기 위해 발전된 방법 (Silhouette Method)
- 각 데이터가 해당 데이터와 같은 군집 내의 데이터와는 얼마나 가깝게 군집화가 되었고, 다른 군집에 있는 데이터와는 얼마나 멀리 분포되어 있는지를 나타내는 지표
- 실루엣 계수 점수가 크다는 건 군집 간의 거리가 멀다는 의미로 잘 군집화 돼 있다고 볼 수 있다.
- 각 군집별 데이터의 수가 고르게 분포되어야 하며, 각 군집별 실루엣 계수 평균값이 전체 실루엣 계수 평균값에 크게 벗어나지 않는 것이 중요.
- 계산하는 공식에 따라 -1 ~ 1 & 0~ 1 사이의 값을 가질 수 있다

Q&A
Q. pariplot을 그리는 이유?
A. scatter > 시간 소요 多. 샘플만 추출 > 시각화 -> 빠르게 출력.
Q. 현실세계에서 양의 상관이 있는것과, 음의 상관이 있는 것?
A. 양의 상관 : 교육 수준과 소득 수준, 기온과 아이스크림 판매량
음의 상관 : 체중과 운동량, 강수량과 관광객 수
Q. 상관계수를 볼 때 주의해야 할 점?
A.
1. 이상치(outliers)에 민감. 이상치가 있을 경우 상관 계수의 값이 크게 왜곡될 수 있으므로, 이상치를 먼저 확인하고 제거한 후 상관 계수를 계산.
2. 선형적인 상관관계만을 고려. 만약 비선형적인 관계가 있는 경우에는 상관 계수를 계산하는 것이 의미가 없을 수 있습니다.
3. 인과관계와 혼동하지 말아야 한다. 상관 계수는 두 변수 간의 관계를 나타내기 때문에, 두 변수 사이에 인과관계가 있는지는 알려주지 않습니다.
4. 샘플 크기에 따라 결과가 달라질 수 있다. 일반적으로 샘플의 크기가 작을 경우에는 상관 계수가 왜곡될 가능성이 높습니다.
5. 다중공선성(multicollinearity)에 주의해야 한다. 두 변수 사이에 강한 상관관계가 있는 경우에는 다중공선성이 발생할 수 있습니다. 이 경우에는 회귀분석 등 다른 방법을 사용하여 문제를 해결해야 합니다.
심슨의 역설(Simpson's paradox)
> 데이터의 세부 그룹별로 일정한 추세나 경향성이 나타나지만, 전체적으로 보면 그 추세가 사라지거나 반대 방향의 경향성을 나타내는 현상을 의미.
Q. 머신러닝, 딥러닝에서 추상화된 도구(Scikit_learn, TensorFlow, PyTorch,Transformer, FastAI)를 사용했을 때의 장단점?
A. 장점
- 개발 시간 단축과 정확성 향상
- 재사용성
- 하드웨어 가속
단점
- 빠르게 실행 할 수 있는 장점있는 방면에 어떻게 동작하는지 알 수 없다. (매커니즘 이해도 부족)
- 사용법이 비교적 간단한 반면 내가 원하는 방식으로 사용하기 어렵다.
- 일부 원하는 기능이 구현되어있지 않을 수 있으며 개발자가 구성할 수 있는 옵션이 적을 수 있다.
- 메모리 사용의 증가
- 특정 프레임워크나 라이브러리에 종속될 우려가 있어 일반성이 부족할 수 있다.
'멋쟁이사자처럼 AI School 8기(fin) > TIL(Today I Learn)' 카테고리의 다른 글
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.10 ) - 태블로2 with 강승일 (0) | 2023.03.10 |
|---|---|
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.8), 머신러닝 (0) | 2023.03.08 |
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.6), RFM (0) | 2023.03.06 |
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.3 ) - 태블로1 with 강승일 (0) | 2023.03.03 |
| [멋쟁이사자처럼 AI스쿨] TIL(23.2.28) (0) | 2023.02.28 |



