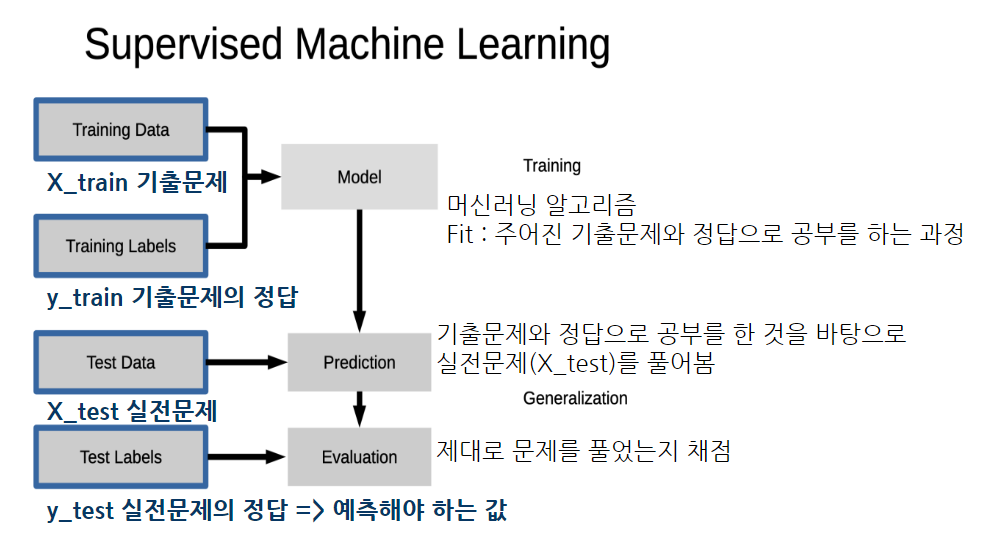
머신러닝 - 지도학습

df.value_counts(1) = df.value_counts(normalize=True)
지니 불순도는 집합에 이질적인 것이 얼마나 섞였는지를 측정하는 지표이며 CART 알고리즘에서 사용한다. 어떤 집합에서 한 항목을 뽑아 무작위로 라벨을 추정할 때 틀릴 확률을 말한다. 집합에 있는 항목이 모두 같다면 지니 불순도는 최솟값(0)을 갖게 되며 이 집합은 완전히 순수하다고 할 수 있다.
Q. 결측치 채우기?
A. 결측치를 채울 때 평균, 중앙값 등으로 채우기도 합니다. 결측치가 너무 많은데 해당 변수가 중요한 값일 때는 제거하는 것보다 채우는 것이 더 나을 수도로 있습니다. 상황에 따라 어떻게 채우느냐에 따라 성능이 나아질 수도 있고 나빠질 수도 있습니다.
머신러닝에서 결측치를 채우는 방법
1) 평균값, 중앙값, 최빈값 등의 대푯값 사용: 해당 열의 결측치를 해당 열의 평균값, 중앙값, 최빈값 등으로 채웁니다.
2) 예측 모델 사용: 해당 열의 값이 결측치인 행을 제외한 나머지 데이터를 이용하여 예측 모델을 만들고, 이를 사용하여 결측치를 채웁니다. 대표적으로 회귀 모델(피처 변수를 통해 예측)이나 K-NN 모델(근처에 있는 값으로 채움)을 사용할 수 있습니다.
3) 시계열 데이터에서의 선형보간, 보간법(pandas interplate) 등: 시계열 데이터의 경우, 이전 시점의 데이터를 이용하여 결측치를 보간하는 방법 등을 사용할 수 있습니다. 결측치 제거: 결측치가 너무 많거나 결측치를 채우는 것이 데이터의 품질을 떨어뜨린다고 판단될 경우, 해당 행 또는 열을 제거하는 방법을 사용할 수 있습니다.
결측치를 채우는 방법은 데이터의 특성에 따라 선택되어야 합니다.
학습, 예측 데이터셋을 나눌 시
1) 직접 판다스로 나누기
2) sckit-learn의 train_test_split을 사용 가능(sckit-learn의 전처리 기능은 다른 딥러닝 라이브러리에서 다수 사용)
+ 학습, 예측 데이터셋을 나눌 때는 학습데이터에 비율을 더 많이 부여하는게 좋다. (대게 5:5, 8:2, 7:3으로 나눔)
=> 공부를 더 많이 하고 시험을 봐야 더 잘 볼 수 있기 때문
Q. 섞에서 나누었을 때 장점
A. 클래스가 여러개일 경우에 클래스의 수가 train, test에 균일하게 나뉘지 않을 수 있음.
train_test_split()의 기능을 사용시, label값을 균형있게 나눌 수 있음.
ex) 이탈 여부 예측시 이탈한다, 안한다가 7:3 정도로 train에 있다면 test에도 7:3으로 들어 있어야 제대로 학습하고 예측
임의로 순서대로 나눌시 train에는 8:2로 들어있는데, test에는 6:4로 들어 있다면 예측의 성능이 떨어질 수도 있음.
불균형한 클래스의 경우 같은 비율로 만들어 줄 때 언더샘플링, 오버샘플링(KNN, smote) 등의 방법을 사용
Q. 섞어서 나누면 안 되는 데이터
A. 순서가 있는 데이터, 시계열 데이터는 섞어서 나누지 않고 순서대로 나눔
Q. 전처리 => train 에만 fit을 하는 이유
train 기준으로 test 데이터도 변환하기 위해 test 에 다시 fit을 하게 되면 기준이 달라지게 됩니다.
* fit => train
* transform => train, test
'멋쟁이사자처럼 AI School 8기(fin) > TIL(Today I Learn)' 카테고리의 다른 글
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.13), RandomForest, OneHotEncoding (0) | 2023.03.13 |
|---|---|
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.10 ) - 태블로2 with 강승일 (0) | 2023.03.10 |
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.7), 머신러닝 (0) | 2023.03.07 |
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.6), RFM (0) | 2023.03.06 |
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.3 ) - 태블로1 with 강승일 (0) | 2023.03.03 |



