Q. 왜 Accuracy 만으로는 제대로 된 분류의 평가를 하기 어려울까?
예를 들어 암 여부를 예측하는 모델이라고 할 때 현실세계에서 건강검진을 했을 때 1000명 중에 1명이 암환자라면 학습을 했을 때 암환자의 특징을 학습하기도 어려울 뿐더러, 정확도인 Accuracy로 측정하게 되면 모두 암환자가 아니라고 했을 때 99.9%가 정확도로 나오게 됩니다.
1명의 암환자를 제대로 찾지 못했기 때문에 해당 모델은 잘 만든 모델이라고 평가할 수 없습니다.


2. 분포 기반의 단어 표현 ( Distributed Representation) : 임베딩, 다차원 공간의 어딘가에 심어 놓았다(embed), 타겟 단어 주변에 있는 단어를 벡터화 하는 방법
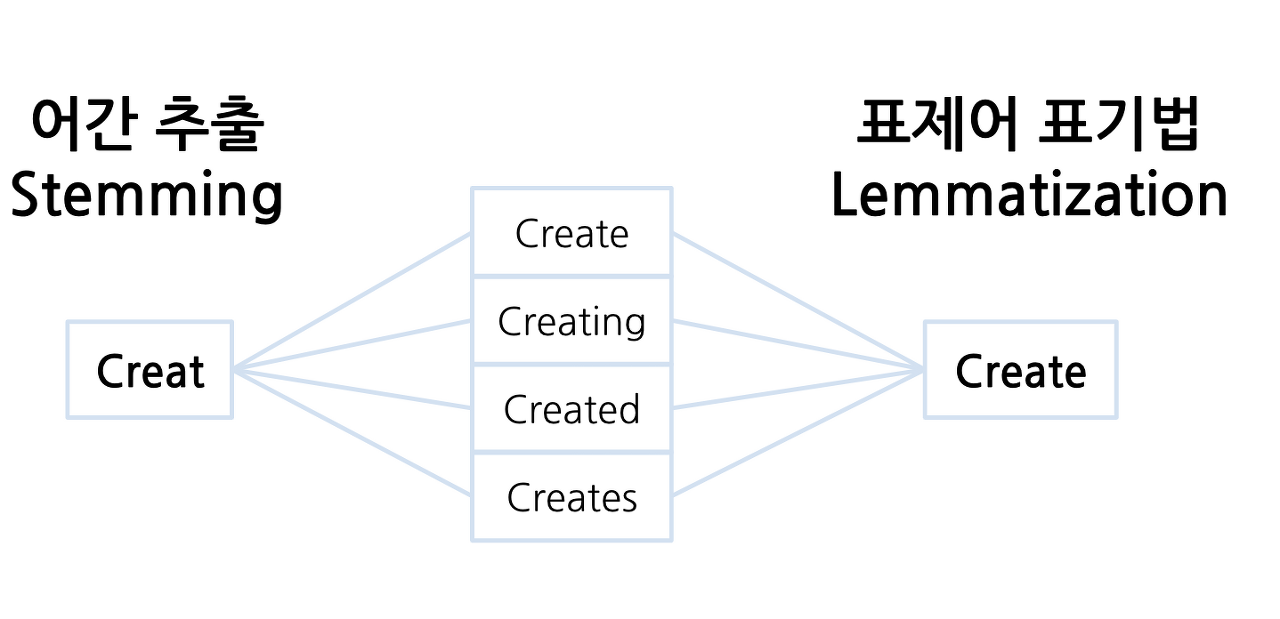
표제어 추출(Lemmatization)
단어들로부터 표제어를 찾아가는 과정
표제어 추출 전 : ['policy', 'doing', 'organization', 'have', 'going', 'love', 'lives', 'fly', 'dies', 'watched', 'has', 'starting'] 표제어 추출 후 : ['policy', 'doing', 'organization', 'have', 'going', 'love', 'life', 'fly', 'dy', 'watched', 'ha', 'starting']
Bag Of Words 단어가방을 만들었을 때 전혀 다른 의미가 같은 의미로 만들어질 수도 있습니다. 이를 보완하려면 어떻게 하면 좋을까요?
Bag-of-Words(BOW)는 텍스트 분석에서 매우 일반적인 방법 중 하나입니다.
그러나 BOW 모델은 문맥과 관련된 정보를 무시하고 각 단어를 독립적인 단위로 취급하기 때문에, 동음이의어나 다의어와 같은 여러 단어들이 동일하게 취급될 수 있습니다.
이러한 문제를 해결하기 위해서는 다음과 같은 방법들이 있습니다:
1. WordNet을 이용하여 단어의 동의어와 다의어를 찾아 대체하는 방법:
WordNet은 영어 단어의 의미 체계를 구축한 데이터베이스로, 유의어, 반의어, 상하위어, 관련어 등을 제공합니다. 이를 이용하여 동의어나 다의어를 찾아 대체하면, 더 정확한 분석이 가능합니다.
2. N-gram을 이용하여 문맥 정보를 포함하는 방법: N-gram은 연속된 N개의 단어들을 하나의 단위로 취급하는 방법입니다. 예를 들어, 2-gram을 적용하면, "I love you"라는 문장은 "I love", "love you"라는 두 개의 단어 쌍으로 분리됩니다. 이를 이용하여 문맥 정보를 포함하면, 동음이의어나 다의어를 더 정확하게 구분할 수 있습니다.
3. 품사 태깅을 이용하여 다의어를 구분하는 방법: 품사 태깅은 문장 내의 각 단어가 어떤 품사인지를 구분하는 작업입니다. 이를 이용하여 다의어를 구분할 수 있습니다. 예를 들어, "bank"라는 단어는 명사로는 은행을 뜻하지만, 동사로는 언덕을 뜻합니다. 따라서, 품사 정보를 이용하여 이를 구분할 수 있습니다. 이러한 방법들을 조합하여 사용하면, 보다 정확한 텍스트 분석이 가능해집니다.
min_df 를 설정했을 때 효과?
- => 오타, 희귀 단어 제거 효과
max_df를 썼을 때의 효과?
- => 자주 등장하지만 큰 의미가 없는 불용어(그, 그리고, 그래서 ,너는 )제거에 효과
max_features
- 기본값 = None
- 벡터라이저가 학습할 기능(어휘)의 양 제한
- corpus중 빈도수가 가장 높은 순으로 해당 갯수만큼만 추출
- 피처가 너무 많으면 계산이 오래 소요. => 단어의 수 제한 시 사용
Q. 원핫인코딩과 단어가방(bag of words)의 차이점?
Q. 단어 가방(bag of words)의 단점?
Q. 단어가방과 TF-IDF 의 차이점
단어가방은 빈도만 보기 때문에 최근 이슈가 되고 있는 "얼룩말 세로"라는 단어는 최근 신문기사에서는 중요한 주제입니다. 그런데 과거 1년치 신문기사를 분석한다면 해당 단어는 빈도가 낮아 중요하지 않는 단어로 볼 수 있습니다. 하지만 특정 기사에서는 "얼룩말 세로" 가 자주 등장하기 때문에 해당 기사에서는 "얼룩말 세로"가 중요한 역할이라 볼 수 있을것입니다.전체 문서에는 자주 등장하지 않지만 특정 문서에 자주 등장하는 단어에 가중치를 주는 것이 TF-IDF
Q. 단어 가방으로 벡터화 했을 때와 TF-IDF로 벡터화 했을 때 어떤 차이점이 있을까요?
CountVectorizer() 에서는 같은 1로 표현되던 경우도 상대적으로 가중치를 비교
CountVectorizer
사이킷런에서 제공하는 bags of words를 만드는 방법
텍스트 문서 모음을 토큰 수의 행렬로 변환해줌 단어들의 출현빈도로 문서들을 벡터화
- analyzer : 벡터화 방법의 단위 (단어/문자/char_wb)
- ngram_range : 단위수. (1, 3)이라면 토큰을 1~3개까지 묶어서 벡터화
- max_df : 임계값보다 높은 용어는 제외, 불용어를 처리할 수 있음
- min_df : 임계값보다 낮은 용어는 제외. 오타나 희귀단어 제거
- stop_words : 불용어 처리
불용어
유의미한 단어 토큰만을 선별하기 위해서는 큰 의미가 없는 단어 토큰을 제거하는 작업
I, my, me, over, 조사, 접미사 같은 단어들은 문장에서는 자주 등장하지만 실제 의미 분석을 하는데는 거의 기여하는 바가 없는 경우가 있습니다. 이러한 단어들을 불용어(stopword)라고 합니다.
'멋쟁이사자처럼 AI School 8기(fin) > TIL(Today I Learn)' 카테고리의 다른 글
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.29) svd, 토픽모델링 (1) | 2023.03.29 |
|---|---|
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.28) 텍스트 분석, 자연어처리2 (0) | 2023.03.28 |
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.22) confusion matrix (0) | 2023.03.22 |
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.21) XGBoost, LightBGM (1) | 2023.03.21 |
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.20), RandomSearchCV (0) | 2023.03.20 |



