
Numpy
- 대규모의 수학연산 시 속도 지연을 보완
- 행렬, 다차원 배열 쉽게 처리
- 데이터 구조 외 수치계산을 위한 효율적으로 구현된 기능 제공
Numpy가 빠른 이유
- 벡터화 → 간결하고 읽기 쉬움
- 코드는 표준 수학적 표기법과 비슷, 버그가 적음
- 내부적으로 반복 사용 x
- 산술 연산 및 논리적, 비트 단위, 기능적 등의 모든 연산이 브로드캐스트 방식으로 동작
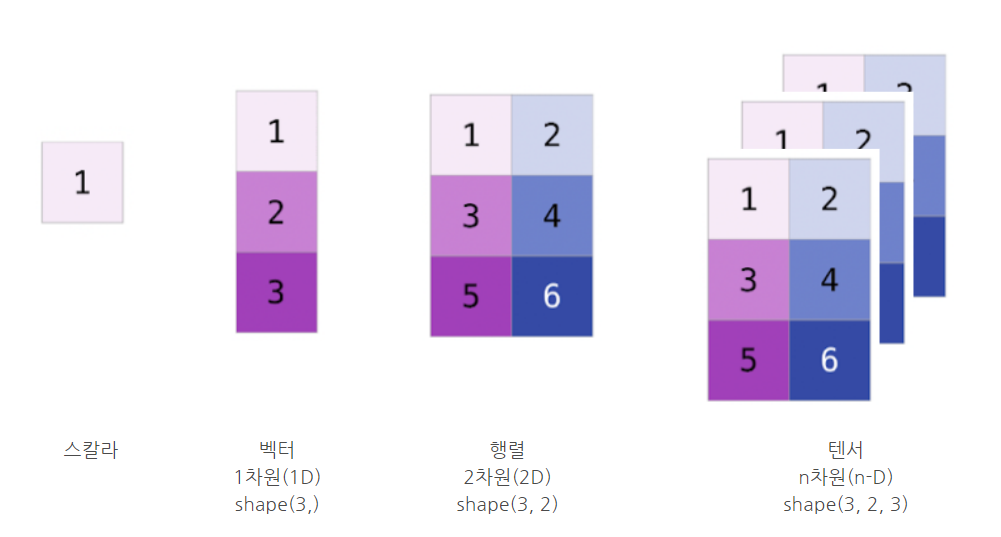
- (벡터, 행렬 연산)
Numpy의 zeros, ones, zeros_like, ones_like
→ 삼각 행렬 마스크
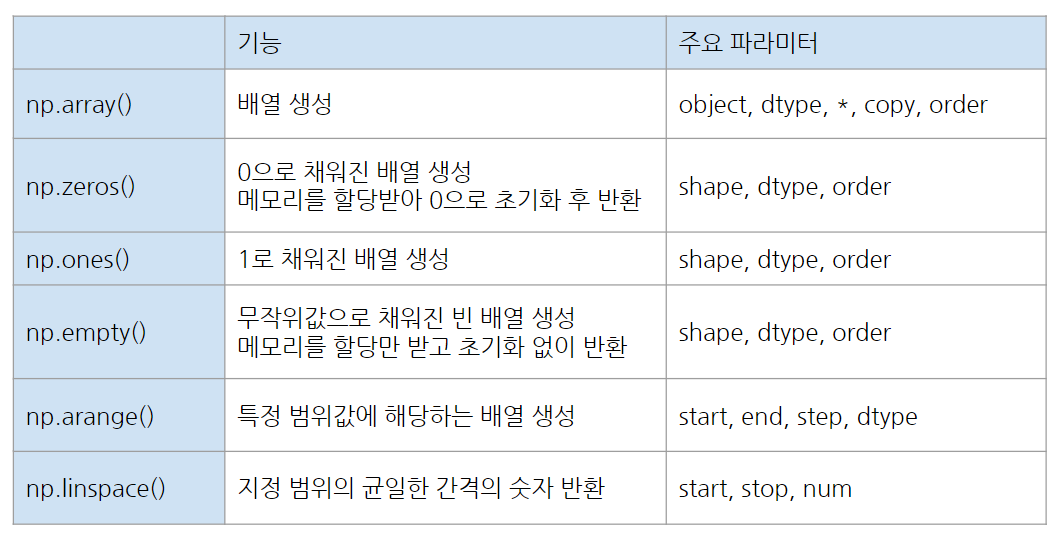
numpy 배열 생성
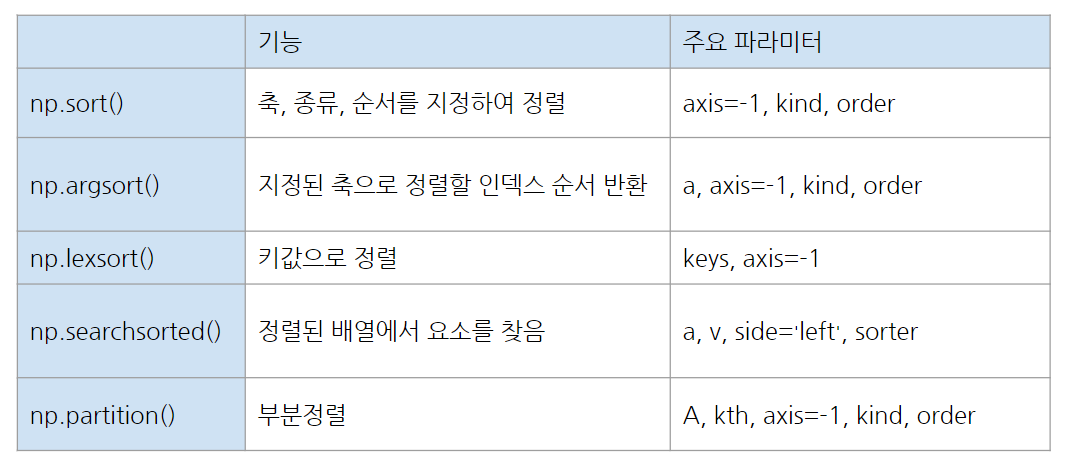
numpy 정렬
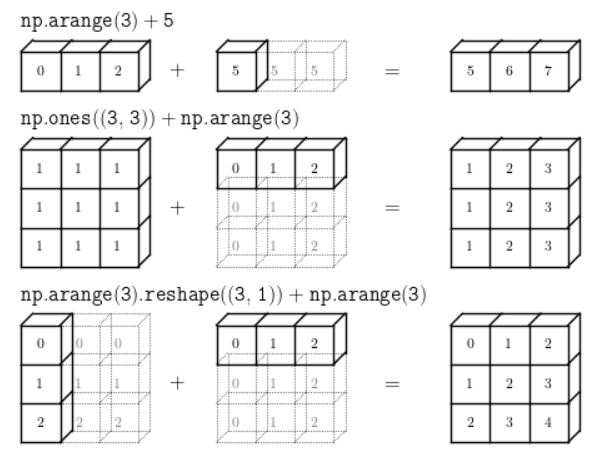
numpy 브로드캐스팅(Broadcasting)
> 모양이 다른 배열들 간의 연산이 어떤 조건을 만족했을 때 가능해지도록 배열을 자동적으로 변환하는 것
1. 맴버가 하나인 배열은 어떤 배열에나 브로드캐스팅(Broadcasting)이 가능(단, 맴버가 하나도 없는 빈 배열을 제외)
ex) 4x4 + 1
2. 하나의 배열의 차원이 1인 경우 브로드캐스팅(Broadcasting)이 가능
ex) 4x4 + 1x4
3. 차원의 짝이 맞을 때 브로드캐스팅(Broadcasting)가능
ex) 3x1 + 1x3
np.where(Z > 0.5, 0, 1)
> 확률값으로 반환받아 특정 임계치에 따라 클래스 값 지정
가산혼합 => 모든 값을 더하면 흰색
감산혼합 => 모든 값을 더하면 검정색

행렬 곱셈(matrix multiplication)
> 두 개의 행렬에서 한 개의 행렬을 만들어내는 이항연산.
첫째 행렬의 열 개수와 둘째 행렬의 행 개수가 동일해야한다.
( N x M ) X ( M x Z ) = (N, Z)
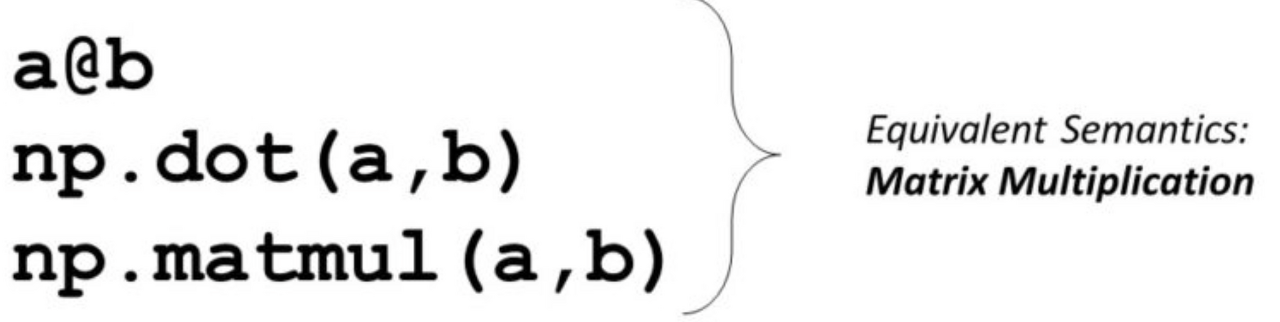
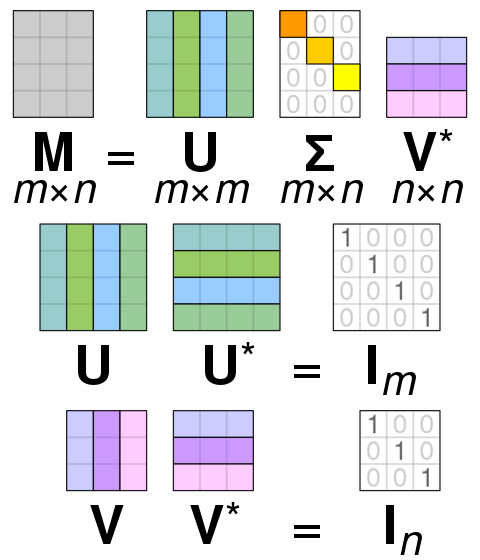
SVD
토픽 모델링(Topic model)
- 문서 집합의 추상적인 "주제"를 발견하기 위한 통계적 모델 중 하나
- 텍스트 본문의 숨겨진 의미구조를 발견하기 위해 사용되는 텍스트 마이닝 기법
잠재 디리클레 할당 (Latent Dirichlet allocation, LDA)
- 주어진 문서에 대하여 각 문서에 어떤 주제들이 존재하는지를 서술하는 확률적 토픽 모델 기법
- 미리 알고 있는 주제별 단어수 분포를 바탕, 주어진 문서에서 발견된 단어수 분포를 분석
- 해당 문서가 어떤 주제들을 함께 다루고 있을지를 예측
- 기본적으로 빈도 수 기반 단어-문서 매트릭스를 입력으로 사용,
- 주어진 텍스트 데이터 집합에서 존재하는 잠재적인 토픽을 찾아냄.
- 각 토픽은 단어 분포를 가지며, 토픽 모델링을 수행하려는 텍스트 데이터에 대한 문서의 토픽 분포와 관련
- 베이지안 토픽 모델링의 일종, 각 문서가 토픽에 속할 확률과 각 단어가 특정 토픽에 속할 확률을 계산
- Dirichlet 분포를 사용하여 토픽 분포와 단어 분포의 사전 분포를 정의, Gibbs 샘플링을 사용, 파라미터 추정
- 텍스트 데이터에서 토픽을 추출하는 데 유용, 문서 분류, 정보 검색, 추천 시스템 등 다양한 응용 분야에서 사용
- 주요 파라미터
- n_components: 추출할 토픽의 수를 결정. 기본값은 10
- max_iter: Gibbs 샘플링 알고리즘이 실행될 최대 반복 횟수를 결정. 기본값은 10
- learning_method: Gibbs 샘플링 알고리즘에 사용되는 추론 방법을 결정.
- 'batch'는 배치 방식으로 계산,
- 'online'은 온라인 방식으로 계산. 기본값은 'batch'
- learning_decay: 온라인 학습 방법에서 이전 반복에서 추정된 파라미터 값을 사용하는 비율을 결정. 기본값은 0.7
- learning_offset: 온라인 학습 방법에서 처음 시작할 때 파라미터 값에 추가되는 가중치를 결정. 기본값은 10
- random_state: 결과의 재현성을 위해 사용되는 시드 값. 기본값은 None
- n_jobs: 병렬 처리를 위해 사용되는 CPU 코어의 수를 결정. 기본값은 1, -1을 지정하면 모든 가능한 코어가 사용
pyLDAvis
- 문서에 대한 클러스터 연관성을 찾는 데 사용되는 확률론적 모델.
- 두 가지 확률 값을 사용하여 문서를 군집화.
- P(단어 | 주제): 특정 단어가 특정 주제와 연관될 확률. 이 첫 번째 확률 집합은 워드 X 주제 행렬로도 간주.
- P(주제 | 문서): 문서와 관련된 항목. 이 두 번째 확률 집합은 주제 X 문서 행렬로 간주.
- 확률 값은 모든 단어, 주제 및 문서에 대해 계산.
- pyLDAvis 는 사용자가 텍스트 데이터 코퍼스에 맞는 토픽 모델의 토픽을 해석할 수 있도록 설계
- 패키지는 적합한 LDA 주제 모델에서 정보를 추출하여 대화형 웹 기반 시각화
- 시각화는 IPython 노트북 내에서 사용하기 위한 것이지만 쉽게 공유할 수 있도록
- 독립 실행형 HTML 파일로 저장할 수도 있음(*참고: LDA는 잠재 Dirichlet 할당을 나타냄)
'멋쟁이사자처럼 AI School 8기(fin) > TIL(Today I Learn)' 카테고리의 다른 글
| [멋쟁이사자처럼 AI스쿨] TIL(23.4.7) 알고리즘, 자료구조 week2(with 이호준) (0) | 2023.04.10 |
|---|---|
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.31) 알고리즘, 자료구조 week1(with 이호준) (0) | 2023.03.31 |
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.28) 텍스트 분석, 자연어처리2 (0) | 2023.03.28 |
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.27) 텍스트 분석, 자연어처리 (0) | 2023.03.27 |
| [멋쟁이사자처럼 AI스쿨] TIL(23.3.22) confusion matrix (0) | 2023.03.22 |

