AIS8 week13
23.3.13 - 3.15, 머신러닝
0601 파일
- 회귀 모델을 사용해 보기
- 회귀 모델의 평가 측정 공식 R square Score, MAE, MSE, RMSE, RMSLE 알아보기
- ExtraTreeRegressor 모델 사용
- CrossValidation 사용
- 어떤 피처를 선택하는게 중요한지 => Baseline 점수 만들기
0602 파일
- 로그를 변환하고 다시 원래 값으로 복원하는 방법
- GridSearchCV
- Gradient Boosting 모델
모델의 성능을 향상시키는 다양한 방법
- 데이터 수집: 교육 예제의 수 늘리기
- 특성 처리: 더 많은 변수 추가 및 특성 처리(전처리, feature engineering) 향상
- 모델 파라미터 튜닝: 학습 알고리즘에서 사용하는 교육 파라미터의 대체 값 고려
Log Transformation
- log를 count값에 적용하게 되면 한쪽에 너무 뾰족하게 있던 분포가 좀 더 완만한 분포가 된다.
- 어떤 쪽으로 너무 치우치거나 뾰족한 데이터가 완만하게 된다.
- 정규분포에 좀 더 가까운 형태로 만들어준다.
- log를 취한 값을 사용하게 되면 이상치에도 영향을 덜 받는다.
회귀 모델에서 사용할 수 있는 라벨 스무딩(Label Smoothing) 기법
> 문제의 특성에 따라 적절한 방법을 선택
1) 정답 라벨에 노이즈 추가
- 정답 라벨 값에 작은 노이즈를 추가하여 부드러운 라벨 값을 할당합니다.
- 예를 들어, 정답 라벨이 100일 때, 이를 95~105 사이의 값으로 조정하여 노이즈를 추가할 수 있습니다.
2) 로그 변환
- 정답 라벨에 로그 변환을 취한 후, 부드러운 라벨 값을 할당합니다.
- 예를 들어, 정답 라벨이 100일 때, 이를 로그 변환하여 2.0으로 만들고, 이 값에 노이즈를 추가하여 부드러운 라벨 값을 할당할 수 있습니다.
3) 표준편차 추가
- 정답 라벨 값에 대해 표준편차를 더해 부드러운 라벨 값을 할당합니다.
- 예를 들어, 정답 라벨이 100이고, 표준편차가 10일 때, 110을 부드러운 라벨 값으로 할당할 수 있습니다.
4) 확률 분포 변환
- 정답 라벨을 부드러운 확률 분포로 변환하여 부드러운 라벨 값을 할당합니다.
- 예를 들어, 정답 라벨이 100이고, 표준편차가 10일 때, 정규 분포를 따르는 확률 분포에서 무작위로 값을 뽑아 부드러운 라벨 값을 할당할 수 있습니다.
squared loss를 더 많이 사용하는 이유 ?
absolute loss를 사용했을 경우에는 기울기가 각 부호에 따라 부호와 같은 기울기가 나오기 때문에
미분을 했을 때 같은 방향 , 같은 미분값이 나와서 기울기가 큰지, 작은지 비교할 수 없다.
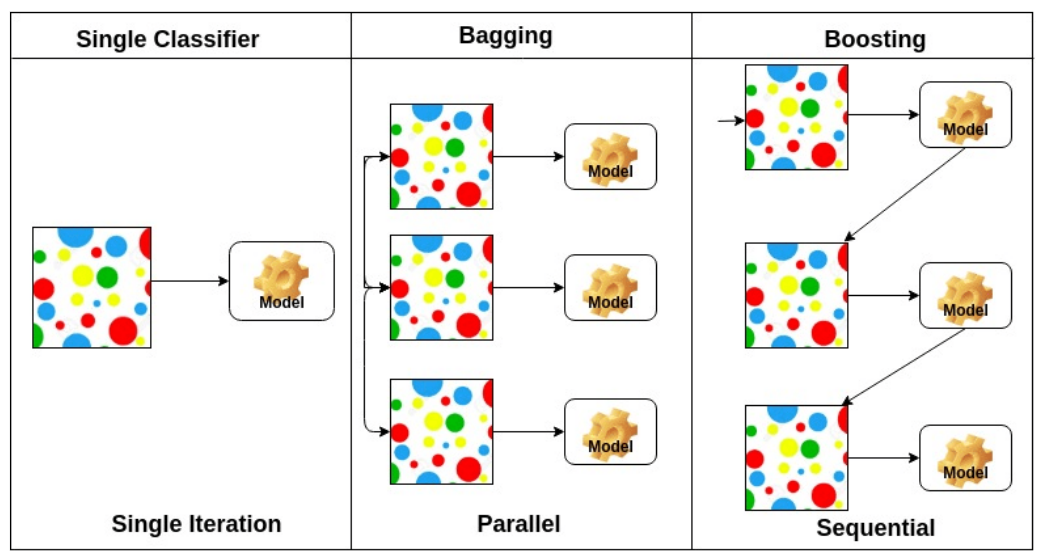
Gradient Boosting Machine
- 가중치를 업데이트하는 부스팅에 경사하강법을 추가한 기계학습법.
- 샘플의 가중치를 수정하는 대신 이전 모델이 만든 잔여 오차에 대해 새로운 모델을 학습.
- 앙상블에 이전까지의 오차를 보정하기위해 샘플의 가중치를 수정할 수 있도록 모델을 순차적으로 추가.
Q. 하이퍼 파라미터
- 모델링할 때 사용자가 직접 세팅해주는 값
- learning rate나 서포트 벡터 머신에서의 C, sigma 값, KNN에서의 k값 등등
- 머신러닝 모델을 쓸 때 사용자가 세팅하는 값
- 정해진 최적의 값이 없지만. 휴리스틱한 방법이나 경험 법칙(rules of thumb)에 의해 결정하는 경우가 많다.
- 자동으로 하이퍼 파라미터를 선택해주는 라이브러리를 사용하기도.
Q. 하이퍼 파라미터를 최적화하는 방법
- 자체적으로 Cross Validation도 진행하여 가장 검증된 하이퍼 파라미터 값을 얻을 수 있다.
SVM(support vector machine, SVM)
기계 학습의 분야 중 하나로 패턴 인식, 자료 분석을 위한 지도학습 모델이며, 주로 분류와 회귀 분석을 위해 사용.
GridSearchCV
GridSearchCV 는 교차 검증 점수를 기반으로 머신러닝 모델의 최적의 파라미터를 검색
하이퍼파라미터를 순차적으로 입력해 학습을 하고 측정을 하면서 가장 좋은 파라미터를 알려줌
트리 학습 후 오차를 측정
gradient를 이용 -> 오차가 최소가 되는 지점을 찾는다!
lerning_rate : 오차가 최소가 되는 지점을 찾을 때, 최적의 가중치를 향해 얼마나 빨리 또는 느리게 이동할지 결정 (보폭)
너무 크면 최소가 되는 지점을 찾지 못하고 지나침(발산) 너무 작으면 속도가 매우 느림
learning rate 가 너무 크면? => 발산
learning rate 가 너무 작으면? => 느림
n_estimators : 학습의 횟수를 의미한다! epoch와 유사 오차가 보완된 트리를 학습
Q. 왜 loss의 기본값이 absolute가 아니라 squared일까?
> absolute : 기울기가 계속 같다가 한 점에서 미분 불가능하고, 이후 부호가 바뀐다
squared : 기울기의 변화량이 점점 작아지다가 0이 된다.
Q. GridSearch 에서 RMSE 로 평가하는 이유?
정답에 이미 로그를 취해주었기 때문에 RMSLE가 아닌 RMSE 로 평가.
피처가 변경이 되면 하이퍼파라미터도 그에 따라 달라질 수 있음.
모델이 다 만들어지고 나서 가장 마지막에 최적의 하이퍼파라미터를 찾는데, 모델 여러 개를 반복문으로 구현시
여러 모델을 함께 비교 가능.
Q. verbose
> 함수 수행시 발생하는 상세한 정보들을 표준 출력으로 자세히 내보낼 것인가를 나타냄.
보통 0 은 출력하지 않고, 1은 자세히, 2는 함축적인 정보만 출력하는 형태
Q. SOTA
> State-of-the-art'의 약자로, '현재 최고 수준의 결과'를 가진 모델로, 현재 수준에서 가장 정확도가 높은 모델을 의미
'멋쟁이사자처럼 AI School 8기(fin) > WIL(Week I Learn' 카테고리의 다른 글
| [멋쟁이사자처럼 AI스쿨] week14 - WIL (1) | 2023.03.23 |
|---|---|
| [멋쟁이사자처럼 AI스쿨] week12 - WIL (0) | 2023.03.09 |
| [멋쟁이사자처럼 AI스쿨] 3월 1주 WIL (0) | 2023.03.02 |
| [멋쟁이사자처럼 AI스쿨] Week8 - WIL (0) | 2023.02.09 |
| [멋쟁이사자처럼 AI스쿨] Week7 - WIL (0) | 2023.02.02 |



