ㅁ ROLLUP
> 집계된 데이터에서 그룹별 소계, 총계를 구하기 위해 사용
group by rollup(컬럼명)
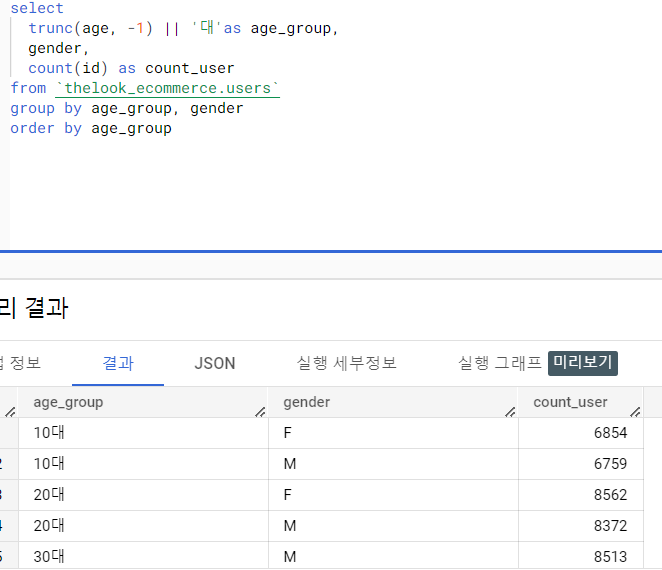
rollup 사용시
소계를 원하는 컬럼명을 추가

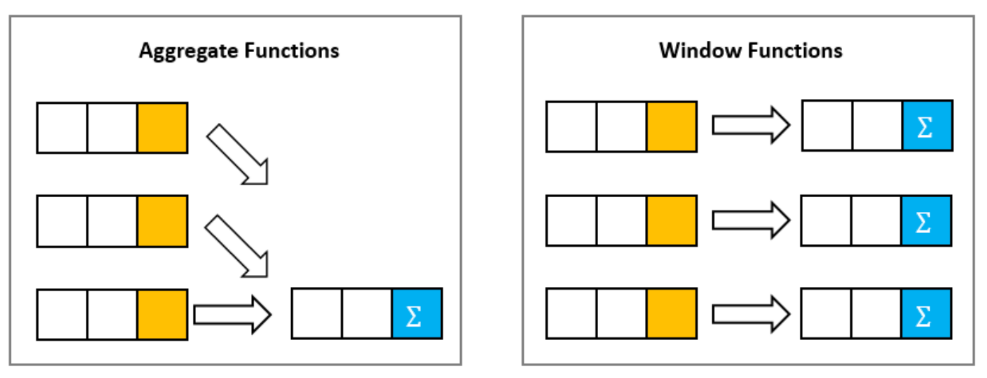
ㅁ Window 함수
분석함수. 현재 행과 관련이 있는 테이블 행들에 대해 계산을 수행
행 그룹의 값을 계산하고 각 행마다 하나의 결과를 반환
cf) 집계함수: 행 그룹에 대해 하나의 결과를 반환하는 집계 함수
WINDOW_FUNCTION (expression)
OVER (
[ PARTITION BY 컬럼 ]
[ ORDER BY 컬럼 ]
[ WINDOWING 절 ]
)
윈도우 함수를 사용하면 이동 평균, 항목의 순위, 누적 합계를 계산, 기타 분석을 수행. 각 행마다 단일 값을 반환
- 탐색 함수 : LEAD, LAG, FIRST_VALUE, LAST_VALUE
- 번호 지정 함수 : RANK, DENSE_RANK, PERCENT_RANK, CUME_DIST, NTILE
- 집계 분석 함수 : 집계 함수들, AVG, COUNT, SUM, MAX, MIN
- 그룹 내 순위 관련 함수(RANKING FAMILY)
- RANK, DENSE_RANK, ROW_NUMBER
- 그룹 내 집계 관련 함수(WINDOW AGGREGATE FAMILY)
- SUM, MAX, MIN, AVG, COUNT
- 그룹 내 행 순서 관련 함수
- LAG, LEAD, FIRST_VALUE, LAST_VALUE, NTH_VALUE
- 그룹 내 비율 관련 함수
- CUME_DIST, PERCENT_RANK, NTILE
함수 이름(컬럼, OFFSET) OVER (PARTITION BY 파티션_컬럼 ORDER BY 정렬_컬럼)
OFFSET : 값을 가져올 행의 위치. 기본 값은 1이고 생략 가능
함수 이름(컬럼) OVER (PARTITION BY 파티션_컬럼 ORDER BY 정렬_컬럼)
필요에 따라 PARTITION BY는 생략 가능
RANK()
파티션 내에서 현재 행의 순위를 부여한다. 동일 값인 경우 동일 순위가 부여되고, 다음 순위는 동일값의 수만큼 건너뛰어 부여
select
id,
first_name,
last_name,
country,
age,
RANK() OVER ( ORDER BY age ) AS rank_number_in_all,
from `thelook_ecommerce.users`
where id between 1 and 20
order by age

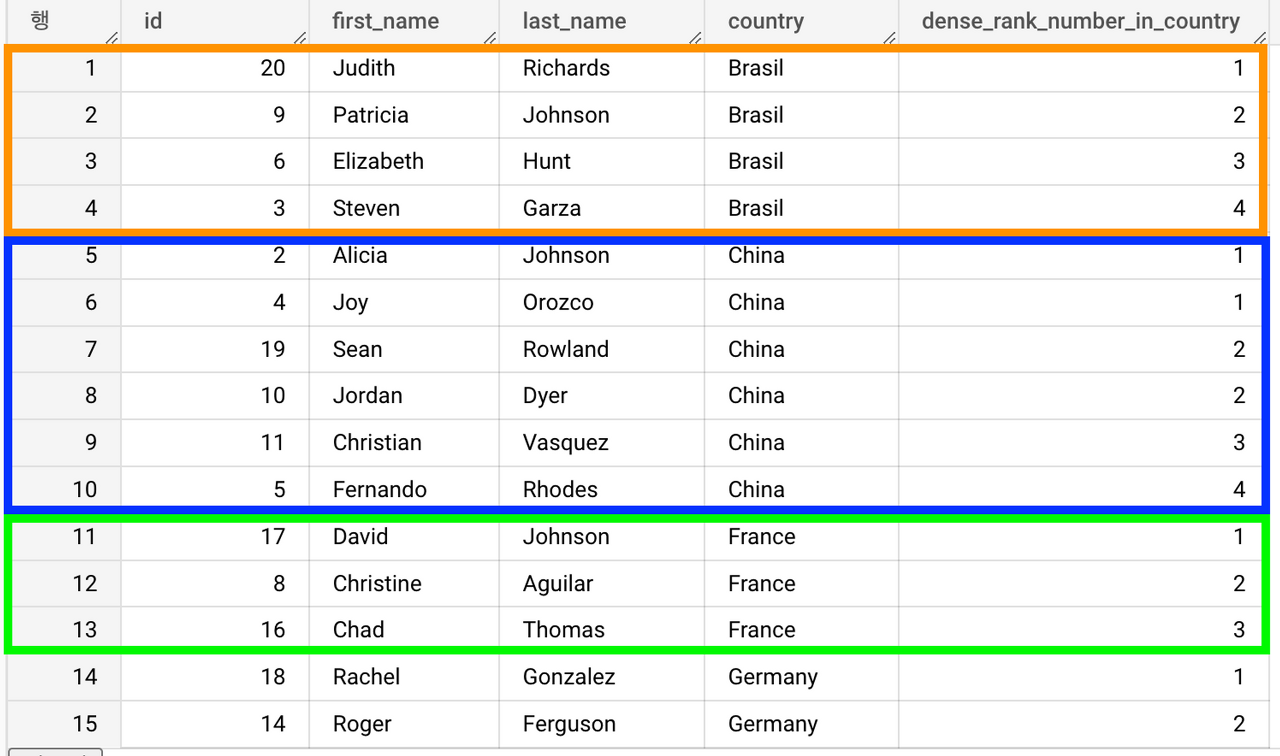
DENSE_RANK()
파티션 내에서 현재 행의 순위를 부여한다. 동일 값인 경우 동일 순위가 부여되고, 다음 순위는 건너뛰지 않고 순차 번호로 부여 된다.
# rank_number_in_country : 유저의 국가내 나이순 랭킹
select
id,
first_name,
last_name,
country,
age,
RANK() OVER ( PARTITION BY country ORDER BY age ) AS rank_number_in_country,
from `thelook_ecommerce.users`
where id between 1 and 20
order by country, age
ROW_NUMBER()
파티션 내에서 1부터 순차적으로 하나씩 증가하는 번호를 생성
# order_number_in_country : 유저의 국가내에서 나이순 번호(나이가 같은 경우 순차적으로 번호 부여)
select
id,
first_name,
last_name,
country,
ROW_NUMBER() OVER ( PARTITION BY country ORDER BY age ) AS order_number_in_country,
from `thelook_ecommerce.users`
where id between 1 and 20

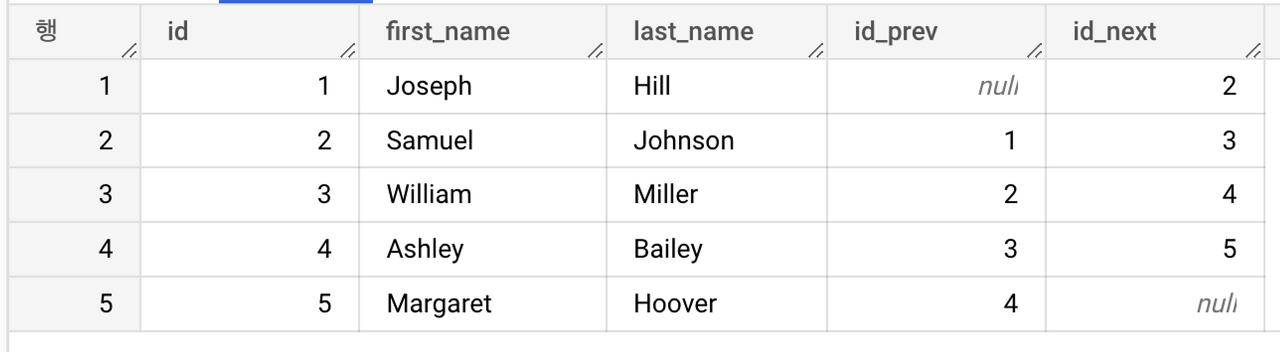
LAG, LEAD
LAG는 이전 행의 필드를 읽고, LEAD는 다음 행의 필드를 읽습니다.
select
id,
first_name,
last_name,
lag(id) over(order by id) as id_prev,
lead(id) over(order by id) as id_next,
from `thelook_ecommerce.users`
where id in (1,2,3,4,5)
order by id
FIRST_VALUE, LAST_VALUE
FIRST_VALUE은 그룹 내의 첫값을 구하고, LAST_VALUE는 마지막 값을 구합니다.
단, LAST_VALUE는 지금까지 읽은 행의 집합을 의미하기 때문에 항상 자기 자신입니다.
전체 그룹에 대한 마지막 값을 구하려면 ROWS 옵션을 주어야 합니다.
NTH_VALUE
현재 윈도우 프레임에 있는 N번째 행의 값을 반환합니다. 이 행이 없으면 NULL을 반환
PERCENT_RANK()
현재 행의 상대적 순위를 반환한다.
계산에 따라 0과 1사이의 범위에서 행의 백분율 순위를 계산
ed) 각 판매 브랜드의 가격에 대한 백분율 순위를 계산
CUME_DIST() - 누적분포
cumulative distribution
특정한 컬럼의 값을 기준으로 순위에 따른 누적 분포 비율을 반환합니다.
- 0보다 크고 1보다 작거나 같은 값이 나옴.
- n보다 값이 작은 행의 갯수 / 현재 window 또는 파티션의 row 개수
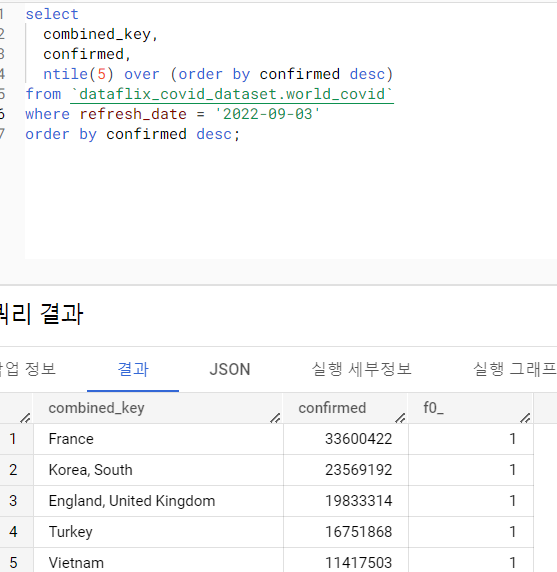
NTILE(n)
레코드의 집합을 n개의 영역으로 구분하고 소속 영역을 구한다. 인수 n은 나눌 영역의 개수를 지정
'멋쟁이사자처럼 AI School 8기(fin) > TIL(Today I Learn)' 카테고리의 다른 글
| [멋쟁이사자처럼 AI스쿨] Day-29 TIL (0) | 2023.02.07 |
|---|---|
| [멋쟁이사자처럼 AI스쿨] Day28 TIL (1) | 2023.02.06 |
| [멋쟁이사자처럼 AI스쿨] Day-25 TIL (0) | 2023.02.01 |
| [멋쟁이사자처럼 AI스쿨] Day24 TIL (0) | 2023.01.31 |
| [멋쟁이사자처럼 AI스쿨] Day23 TIL (1) | 2023.01.30 |



