이미지의 사이즈가 불규칙하면 학습을 할 수 없기 때문에 리사이즈할 크기를 지정
# 이미지가 너무 작으면 왜곡이 되거나 특징을 잃어버릴 수도
# 하지만 계산량이 줄어들어 학습속도가 빨라짐
# 이미지가 너무 크면 확대를 하여 왜곡이 될 수도 있지만, 더 자세하게 학습
# 하지만 계산량이 많아서 시간이 오래 소요 => 원본이미지, 계산 시간, 계산 성능에 대한 신뢰를 고려해서 설정
CNN(합성곱신경망)
Convolution Neural Network
-다층 퍼셉트론(MLP)로 이미지를 flat하게 펼쳐 학습하면 이미지의 지역적 정보(topological information) 소실
>> 합성곱층의 뉴런은 수용 영역(receptive field)안에 있는 픽셀에만 연결하여 이미지의 지역적 정보를 보유

- 다층 퍼셉트론(MLP)은 해당 데이터를 추상화시키지 않고 바로 연산을 시작하기에 학습 시간과 능률이 비효율적
>> 이미지를 이해하고 추상화된 정보 추출하여 특징(feature)의 패턴을 파악하는 CNN 도입
다층 퍼셉트론(MLP)은 이미지 픽셀마다 다른 가중치(W)값을 부여하여, 픽셀값 하나만 달라져도 다르게 계산됨
>> 객체의 위치가 바뀌어도 같은 특징을 추출하도록 합성곱층에서는 각 영역의 인접 데이터를 조사해 특징을 파악
- CNN은 사람의 시신경 구조를 모방한 구조로 데이터를 feature(특징, 차원)로 추출하여 패턴을 파악하는 구조
- 유효 수용 필드(receptive field)가 인간 눈의 중심와와 매우 밀접한 관계가 있으며, 이는 날카로운 중심 시력, 원추 세포의 고밀도 영역 효과를 생성 >> CNN 네트워크에도 자연스럽게 존재: 특징 추출하여 특징의 패턴 파악하여 인식
CNN이 기존 완전 연결 계층(Fully Connected Neural Network)와 비교하여 가진 차별성
- 필터: 각 레이어의 입출력 데이터의 형상 유지, 복수의 필터로 이미지의 특징 추출 및 학습
>> 필터를 공유 파라미터로 사용하기 때문에, 일반 인공 신경망과 비교하여 학습 파라미터가 매우 적음
- 합성곱층: 입력 데이터의 특징을 추출하여 특징들의 패턴을 파악, 이미지의 공간 정보를 유지하면서 특징을 인식
- 풀링층: 추출한 이미지의 특징을 모으고 강화하는 레이어
CNN은 이미지와 같이 이미지의 특징을 추출하는 부분과 클래스를 분류하는 부분으로 구성
- 특징 추출 영역: 합성곱층(필터적용, 활성화 함수 반영)과 풀링층(선택적)을 여러 겹 쌓은 형태
- Flatten 레이어: 추출된 주요 특징을 전결합층에 전달하기 위해 이미지 형태의 데이터를 배열 형태(1차원)로 flat
- 클래스 분류 영역: CNN 마지막 부분에는 이미지 분류를 위한 완전 연결 계층(FC) 추가
- 딥러닝에서 심층 신경망으로 분류되며, 시각적 영상 분석에 주로 적용(이미지 및 비디오)
- 동영상 인식과 분류, 추천 시스템, 의료 영상 분석, 정보추출, 문장분류, 얼굴인식 및 자연어 처리 등에 응용
- 예) 자율 주행 차량은 카메라, 레이더 및 레이저와 같은 감각 입력 장치로 물체 감지를 수행하는 이미지화에 이용
채널(Channel)
- 이미지 픽셀 하나하나는 실수(float)이며, 이미지 형태(shape)는 (높이, 폭, 채널)로 구성
- 컬러 사진은 천연색을 표현하기 위해 각 픽셀을 RGB 3개의 실수로 표현한 3차원 데이터로 3개의 채널로 구성
- 흑백 사진은 흑백 명암만을 표현하는 2차원 데이터로 1개 채널로 구성 ex) (39,31,1)
>> 입력 데이터에는 한 개 이상의 필터가 적용되며, 1개 필터는 특징맵(Feature Map)의 채널이 됨
합성곱층(Convolution Layer)에 n개의 필터가 적용된다면 출력 데이터는 n개의 채널을 생성
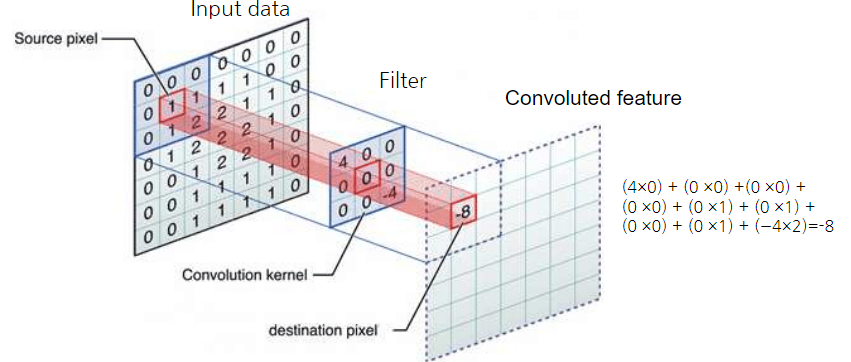
합성곱(Convolution)
데이터의 특징을 추출 과정으로 필터를 사용하여 각 영역의 인접 데이터를 조사해 특징을 파악하여 한 장으로 도출
>> 여기서 도출된 장을 합성곱층(Convolution layer)로 명명(합성곱 처리 결과로부터 피처맵을 생성)
- 이미지의 특정 부분을 추상화하여 특정층으로 표현 (예. 고양이의 눈, 귀, 입을 추상화)
- 하나의 압축 과정으로 파라미터의 개수를 효과적으로 축소
합성곱(Convolution)의 구
- 필터(Filter)와 활성화함수(Activation Function)으로 구성
- 필터(Filter)는 특징(feature)이 데이터에 있는지 없는지 검출하여 가중치 부여(만약 데이터가 있다면 1, 없다면 0)
>> 합성곱층 내 수용영역(receptive field) 생성, 필터(filter) 또는 커널(kernel)이라 혼용하여 명명
- 활성화 함수는 특징 유무를 수치화하기 위해 비선형 값으로 바꿔주는 함수(필터로 분류된 데이터가 대상)
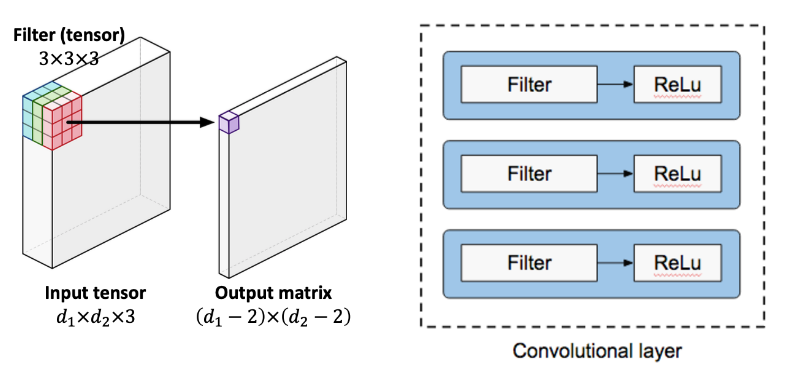
필터(Filter) & 커널(Kernel)
- 필터는 이미지의 특징을 찾아내기 위한 공용 파라미터로 학습의 대상이며, 합성곱의 가중치에 해당
- 커널(kernel): sliding window 하는 영역에서의 크기 ex) 4x4 or (4, 4)이나 (3, 3)과 같은 정사각 행렬로 정의
- 필터(filter):실제로 커널이 가중치 합산 하는 영역의 크기 ex) 16 필터 수는 특징맵 수와 같음
- 필터는 입력 데이터를 지정된 간격으로 순회하며 채널별로 합성곱을 하고 특징맵(모든 채널의 합성곱의 합)을 생성
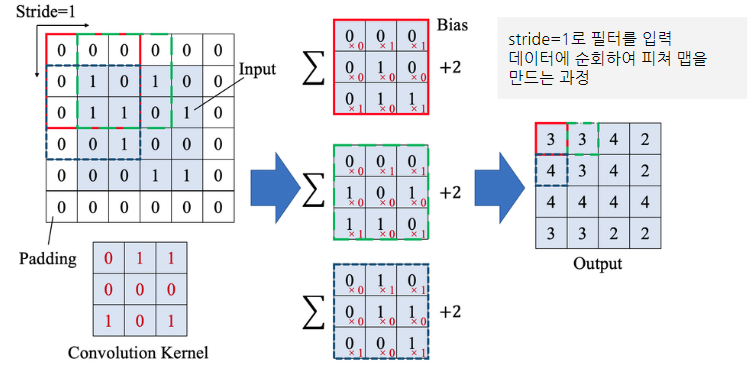
스트라이드(Stride)
- 스트라이드(stride)는 필터를 적용하는 간격을 의미
- 필터는 입력 데이터를 지정한 간격으로 순회하면서 합성곱을 계산 >> 지정된 간격을 Stride로 설정
- stride=1이면 필터를 한 번에 한 픽셀씩 이동 ex) stride= 2로 설정되면 필터는 2칸씩 이동하면서 합성곱을 계산
>> stride를 높일 수록 공간적으로 더 작은 출력 볼륨이 생성(stride를 높일 수록 데이터 손실 고려 필요)
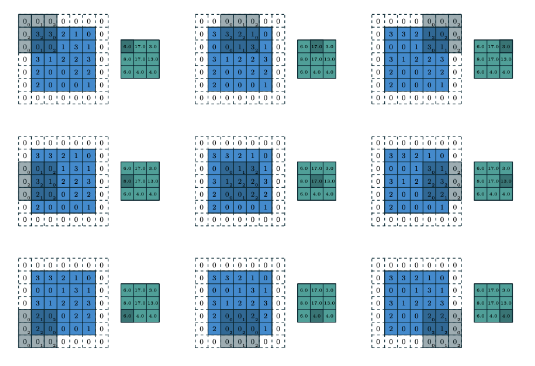
패딩(Padding)
- 문제점: 합성곱층에서 필터와 스트라이드 작용으로 특징맵의 크기는 입력데이터보다 작아짐(손실)
>> 해결 방안인 패딩은 입력 데이터의 외곽에 지정된 픽셀만큼 특정 값으로 채워 넣음(보통 0으로 패딩 값 채움)
- 패딩은 합성곱층의 출력 데이터의 사이즈를 조절하는 기능
- 또한 외곽을 “0”값으로 둘러싸는 특징으로 부터 인공 신경망이 이미지의 외곽을 인식하는 학습 효과도 줄 수 있음
특징맵(Feature Map)
- 합성곱층(Convolution layer)의 입력 데이터를 필터가 순회하며 합성곱을 통해서 만든 출력(행렬)
>> 입력 데이터에서 필터를 통해 불필요한 정보를 걸러내고 중요한 신호만을 추출한 것
- 특징맵의 크기(FM_size) = (input size + 2*padding - filter size)/stride + 1
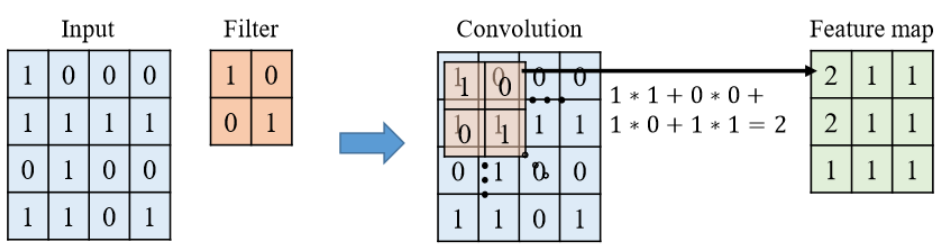
액티베이션 맵(Activation Map)
- Activation Map: 필터를 통해 추출된 피쳐 맵에 활성화 함수(Activation function)를 적용한 최종 출력층
- 활성화 함수: 특징맵의 행렬 값(정량적인 값)을 특징이 “있다 없다”의 비선형 값으로 바꿔 주는 과정
(선형함수 h(x)=cx를 활성화 함수로 사용한다면, y(x)=h(h(h(x)))로 y(x)=c^3x와 똑같은 식으로 은닉층이 없는 네트워크와 같음)
풀링(Pooling)
- 역할: 합성곱층에서 받은 최종 출력 데이터(Activation Map)의 크기를 줄이거나 특정 데이터를 강조
>> 데이터의 사이즈를 줄여주며 노이즈를 상쇄시키고, 미세한 부분에서 일관적인 특징을 제공
- 풀링 레이어를 처리하는 방법: Max Pooling(최대값)과 Average Pooling(평균값), Min Pooling(최소값)
- 보통은 합성곱 과정에서 만들어진 특징(feature)들의 가장 큰 값들만 가져와 사이즈를 감소 (Max-pooling)

풀링층은 합성곱층과 비교하여 다음과 같은 특징을 보유
- 학습대상 파라미터(필터)가 없음
- 풀링층를 통과하면 행렬의 크기 감소
- 풀링층를 통한 채널 수 변경 없음
pool_size : 정수 또는 2개 정수의 튜플, 최대값을 취할 창 크기. 풀링 창에서 최대값을 획득. 하나의 정수만 지정하면 두 차원 모두에 동일한 창 길이가 사용
strides : 정수, 2개 정수의 튜플 또는 없음. 기본값이 pool_size. 각 풀링 단계에 대해 풀링 창이 이동하는 거리를 지정.
padding : "valid"또는 "same"(대소문자 구분 안함) 중 하나
- "valid"패딩 없음을 의미
- "same"결과적으로 출력이 입력과 동일한 높이/너비 치수를 갖도록 입력의 상하좌우에 균등하게 패딩
data_format : 문자열, channels_last(기본값) 또는 channels_first. 입력에서 차원의 순서
- channels_last는 모양이 있는 4D 텐서로 (batch, height, width, channels) 기입
- channels_first 입력은 (batch, channels, height, width)
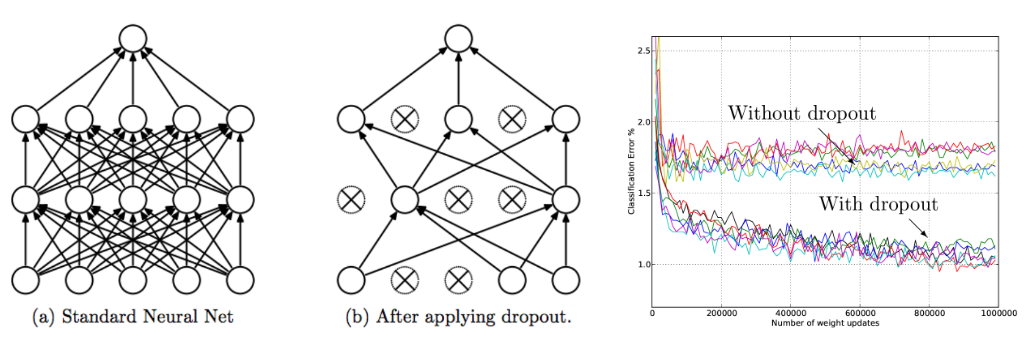
드롭아웃(Dropout)
- 드롭아웃은 AlexNet에서 선보인 과대적합(over-fitting)을 막기 위한 방법
- 신경망이 학습중일때, 무작위로 뉴런을 제거하여(dropout) 학습을 방해함으로 학습 데이터에 과대적합을 방지
- 일반적으로 CNN에서는 이 드롭아웃 레이어를 완전 연결 계층(FC) 뒤에 위치(상황에 따라 max 풀링층 뒤에 위치)
'멋쟁이사자처럼 AI School 8기(fin) > TIL(Today I Learn)' 카테고리의 다른 글
| [멋쟁이사자처럼 AI스쿨] TIL(23.4.19) RNN (0) | 2023.04.19 |
|---|---|
| [멋쟁이사자처럼 AI스쿨] TIL(23.4.18) 전이학습 (0) | 2023.04.18 |
| [멋쟁이사자처럼 AI스쿨] TIL(23.4.12) 딥러닝3 (0) | 2023.04.12 |
| [멋쟁이사자처럼 AI스쿨] TIL(23.4.11) 딥러닝2 (4) | 2023.04.11 |
| [멋쟁이사자처럼 AI스쿨] TIL(23.4.10) 딥러닝 (1) | 2023.04.10 |


